
走向.NET架构设计---第二章:设计 & 测试 & 代码
前言:本篇之所以选择TDD作为例子,主要是由两个原因:1. TDD确实呈现了设计的思路;2. 相对于DDD来说, TDD更加容易上手,学习的曲线没有那么陡峭。
再次申明一下:本系列不是讲述TDD的,只是用TDD来建立设计的思想。即便是用DDD,有时候还是结合TDD一起使用的。
本篇的议题如下:
开发方式比较
什么是设计
设计初探
开发方式比较
我们用下面的一段分析来引出今天的内容:
想想我们平时是如何在写代码:
拿来需求,分析功能,编写功能代码。
这样的方式,没有问题,大家也一直沿用很多年了。为了后面描述方便,我们称这种方式为传统流程。
TDD的怎么做的:
拿来需求,分析功能,写功能测试代码,编写功能代码。
其实两个过程差不多的,真的差不多的。
首先来分析下两种开发流程。个人认为:因为TDD多了一个角色转换的过程:在我们传统流程中,我们一直以一个开发人员的思维在想问题,分析,然后就开始实现。
在TDD中,在分析功能之后,我们就要站在客户的角度(当然很多时候还是我们自己在模拟客户)就要检测这个功能是不是真正需要的,然后在这个前提下,再开始编码。
下面我们再来看一组分析图:

因为从拿到需求和理解需求,到最后的实现,这个过程肯定是有偏差的。就如上图。
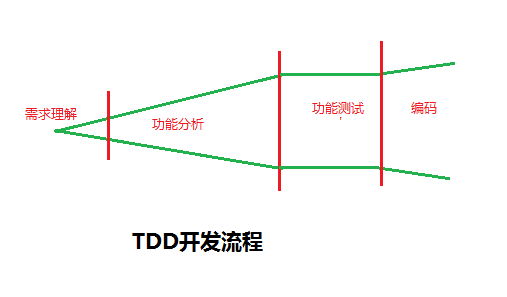
在TDD中,在功能测试那一个环节,就把这种偏差控制了起来。即使最后有偏差,但是小了一些。
为什么要将两种开发的方式比较?
首先,从总体上来看,传统的流程就是先做出基本有用的东西,而且TDD先是搭个架子,然后在做东西。
在TDD中,我们是直奔功能:针对需求出测试,然后针对测试出功能。一针见血。可能这些功能暂时还不能完全用,因为缺少东西,如数据库,在测试中我们可能是模拟的。例如,在实现一个功能的时候,如果这个功能需要操作数据库或者要通过网络访问,那么我们在用传统的方法写的时候,想要看看功能最后实现的效果,往往是debug,或者做出可视化的东西出来,注意力很快就被分散了,如果发现需求理解不对,之前的就重新来过,代价可能而知。而采用TDD的方法,可以先写测试模拟,如用mock, stub等,这样关注点主要在业务上,这种方式就好比水波效应:从中心向周围扩散。
什么是设计
一个软件系统,最重要的就是核心业务功能,系统设计的时候,肯定先是分析功能,并且确认分析的功能是符合需求的,然后再为实现功能寻找解决方案。在有了解决方案的前提下,再考虑上技术的选择,复杂性,可扩展行,可维护性,可行性等,最后就”设计”就产生了,确定实现方案之后,最后实现。”设计”确确实实是一个脑力活。
那么我们就来看看,如何做出一个比较好的设计。
做设计,考虑的太多,太少都不行。多则可能“过度”,少则可能不全。
我们下面就用TDD来帮助我们建立一些设计的思想。
在此之前,有一点我想提出:TDD不是测试,而是设计。如果之前一直以为TDD就是写测试,那么就说明对TDD的理解还在“形”上。
设计初探
我们之前说过:TDD不是测试,更多的是设计的思路。那么为什么在写代码之前写测试可以有个比较好的设计?我们就来体验一下。
我们知道,在面向对象的设计中,有很多的设计原则,例如S.O.L.I.D,在系统中充分的使用这些原则,会导致一个良性的开发过程。所以一个比较的好的设计,应该是尽量的向这些设计原则上面靠拢的。
看一个例子:
例如在用户订单管理系统中有一个需求:客户在下订单的时候首先要去看看自己的账户是否有充足的余额,然后支付,并且把自己所有支付的订单保存起来。(当然这个例子非常的简单,我们这里只是通过简单的例子展示思考的过程)
需求现在已经知道了,实现的技术难度也不大,随便想一下,架子基本就出来了:

传统的设计方法:
大家看看上面的Customer类,很多时候,我们都是这样的写的(其实就是Active Record的实现方式,后面我们会讲述企业架构设计会谈到)。
下面基本就是业务方法ProcessOrder的定义和实现:
代码的架子搭起来了,实现的思路也有了。为了确保业务的理解正确,我们可能需要跟客户或者项目组的人交流,然后再编码实现。在编码的的实现中,该去读数据库的就去读,该插入的数据的就去插入,该怎样就怎样。这样代码写完之后,一般是调试debug( 刚刚开始,为了这个功能写个UI ,不怎么划算) ,看看代码是不是按照我们的意愿在运行。大家应该对这种实现方式没有什么意见吧。
好,现在在处理订单的过程中,有加入了一些要求:如果在Order中,有产品的单价超过了1000的,要通知用户一下。
代码变为:

 代码
代码
然后再调试,查询数据,插入数据,deubg等等,把之前的步骤重复一下。
不知道大家现在是什么感觉。
在上面的例子中,在第一次的代码实现中,为了判断ProcessOrder的正确性,我们加入了数据库的一些操作代码。
第二次的时候只是在业务流程处理中加了一些小的改动,但是我们在调试成本却还是调试流程,调试数据访问代码。也就是说,我们第二次的时候,数据的操作方法没有变化,变化的只是流程的处理,但是为了判断这个ProcessOrder方法的正确性,我们还是走完了整个debug过程。
如果再次在订单处理流程加入新的需求,那么这个方法很快膨胀起来(可能我们会把整个方法分出一些小的子方法),而且调试的成本会越来越高,而且常常重复的调试已经功能完好的代码,如数据访问代码,而且调试一次的所花的时间也越来越多。
或许有人认为这不是个问题。因为我举的例子很简单,如果在一个业务更加复杂的项目中很多的功能都这样,最后的项目最后会怎样?
下面我们就用TDD的设计思想来实现一下,然后大家自己比较:
首先,需求分析还是和之前的一样。
下一步就要确认需求的理解(还是和之前的一样)。
最后开始针对需求写测试代码。
其实这里就有两个问题:
1. 系统中哪些部分要写测试代码?
2. 怎么为这个需求写测试代码?
1. 系统中哪些部分要写测试代码?
我看过一些用TDD开发的项目:几乎是每个方法都有对应的测试代码,而且写的测试代码在最后运行的时候,测试结果居然是通过debug来看的,简直和实现功能代码然后再调试没有区别。
其实测试是有个覆盖率的问题,覆盖率就是:系统中有测试代码的功能代码在所有功能中的百分比。例如系统有100个功能,有30个功能写了测试代码,那么覆盖率就是30%。
当然100%的覆盖率当然好,但是也不是现实,而且也没有必要。一般来说要对系统的核心的业务流程写测试代码,然后再对你认为可能会出现问题的地方写一些测试代码,用来测试如果引入变化后,这部分功能是好的。覆盖率一般是70—80%比较合理,不过得看情况了。.
2. 怎么为这个需求写测试代码?
测试代码都会写,但是写出好的测试代码就不是那么容易的。首先,写测试代码的时候,就得站在用户的角度,看看功能是否正确,不管内部逻辑如何实现的---只看结果,不看过程的,本着这个思想来设计测试代码。打个不恰当的比喻:测试代码就像是一个望子成龙,望女成凤的家长,家长把聪明的小孩送到学校培训,不管怎么样培训,可能学校是请名师来教课,还是通过比赛学习,还是用别的方式,家长不会怎么管,最后,如果小孩成才了,那么就说明你学校有本事,不然,学校就不行。
我们开始写测试代码,我们开始只关注业务流程方面。
(假设没有上面的那个类图了,我们重新设计,因为之间的那个类图用用来讲述传统的设计方式的,忘记上面的那个类图吧)
我们的测试代码可能会这样写:
代码
这样编译肯定会报错的:因为我们系统中还没有这些类。然后我们就加上相应的代码的,是的编译通过。
我们设计一个最直接的Customer类,尽量不写多余的代码:

另外的一个问题来了:
上面的测试代码似乎没有反应什么结果,到底怎么测试?
在开始写测试的时候,会遇到这些问题。现在就要考虑我们之前的那个“家长送孩子上学”的例子了。这里,如果系统订单处理成功,那么就告诉说:OK,成功了,否则就说失败。
测试代码现在改为下面的:
代码
OK ,基本的测试代码就这样了。( 当然有不足的地方,我们后面跟着思考的过程慢慢的完善)
下面我们就要使得测试的代码通过。
我们的专注先是业务流程,而不管什么数据是怎么获取的,从哪里获取的等,避免分散注意力。
下面我们实现ProcessOrder方法:
流程基本如下:
实现的伪码:
代码
大家看到上面的代码后,可能有点奇怪。因为ProcessOrder是一个业务流程,它应该只是关注自己的流程如何处理,如果要数据,找个地方拿,要保存数据,找个东西保存就行了,不管怎么查询和怎么保存。回顾前面的“学校如何教小孩子的方法”。
现在有一点要注意:我们现在关注点是业务流程的正确性,数据从哪里来,其实不重要。
我们现在只是想业务流程跑通,反正测试用的数据都是我们自己设计的,即便数据如果从数据库中来的,而且数据拿来之后,还是得放在内存中的,何必现在就开始写那么多的数据访问代码呢,不如直接用内存中的数据,让流程先跑通,然后在慢慢替换数据访问代码。
好,既然决定数据从内存中拿,说白了就是hard code几个数据,如果把取数据的方法还是放在Customer中,就像之前的传统设计那样。其实是有问题的:此时我们把数据访问的代码还是放在里面,流程通了,然后我们把hard code的代码替换为真正的数据库操作代码,流程也通了。如果像之前:ProcessOrder中,加入了一个新的处理过程,我们加完代码,运行测试,如果测试运行失败了,那么此时是业务流程失败了,还是数据访问代码失败?还要debug进行去吗?如果还得debug,测试的代码的作用何在?还不如一开始就不要测试,直接debug。因为此时导致测试代码不通过的原因有两个了。
所以这里有一个很重要的原则:一个测试方法中,只能有一个让它失败的原因。不然每次运行测试,都要debug分析,是那个原因导致失败。
而且我们知道,在第二次加入新的流程过程的时候,变化的只是业务流程,其实数据访问那块是没有变化的,最后我们还是打开了数据访问代码的所在的类,修改方法,尽管没有修改数据访问方法。所以这些就要把数据访问的代码分析出来,让变化和不变化的独立--—分离变化点,万一数据访问代码也变了,那就让它们单独的变化,这样排错也好点。
那么一个重要的设计原则就要用上:
S--Single Responsibility Principle (SRP)
也是我们常说的”单一职责原则”。意思很好理解:每个对象有仅仅有一个让它变化的因素,也就是说每个对象的只关注一个或者一类功能,不要把很多的不同职能的东西全部糅在一个类里面。
但是上面的类的设计严格的讲,就是违反了SRP原则。因为上面的两个职能:保存业务类的信息和负责持久化数据。
需要增加或者修改一些数据访问的方法,那么这个类就得不断的改动,同理,业务类的流程的变更也改变数据访问代码虽在的类,应该把变化的点剥离出来.

用CustomerRepository来负责持久化Customer业务类的数据。这样变化点就因为SRP原则就分离了。
这样之后,ProcessOrder方法在加了新的处理流程之后,再次运行测试,只要测试不通过,那么可以肯定:流程代码有问题。而且CustomerRepository隐藏数据的来源,几乎没有变化。
其实在我们传统的设计方法中,对于”单一职责”的”渴望”还不是很明显,因为如果改处理流程出了问题,debug进行看看就行了;在TDD的时候,因为加入了测试代码,所以把业务流程代码和数据访问放在一起的设计让测试代码”感觉”到了一点点的迷惑:是流程问题还是别的问题?所以对“单一职责”的“渴望”稍微强了一点,这样在设计时候,起码就能够改善一点点,有点“驱动好的设计”的意思。大家认为呢?
其实”单一职责”不仅仅使用在设计类上,在设计类的方法上也有参考价值,不能把一个方法设计的N复杂。最后还要提写有关TDD的东西:
其实上面的那个测试写的不够好,因为我们测试成功的情况,也要测试失败的情况。我们不能每次都去改测试代码去替换数据。那么我们还不如直接设计两个测试方法,如下:
Public void Test_OrderProcecss _Executed_Successfully_With_ValidateData()
Public void Test_OrderProcecss _Executed_Failed_With_InValidateData()
我们在单元测试的代码中不要访问数据库,Web Service等外部的资源。例如在我们上面的CustomerRepository中,用它参与单元测试的时候,直接把数据hard code。运行单元测试是常常要运行的,如果用外部资源,如果因为网络问题等导致测试失败,就很容易把人搞迷惑:不清楚是功能失败,还是其他的原因。
具体的我们以后再讲述吧!
我是希望尽量把思考的过程通俗的讲出来,所以显得啰啰嗦嗦的!不知道大家是什么感受!希望大家反馈!
最后特别感谢 提出的修改意见!
原文链接: